# Kafka 系列 - 存储机制
Kafka 在设计之初就将数据的持久化视为通常情况,关注点放在了吞吐量而不是功能。Kafka 采取简单的读取和内容附加到日志文件中,这种操作的好处是读写都是 的复杂度,而且读取不影响写入操作。除此之外,数据量的大小对性能几乎没有影响,对于过期的数据也能采取简单方式删除。
Kafka 之所以采用这种读写方式,是因为对磁盘的线性读写比随机读写的性能要快得多,磁盘的线性读在有些情况下甚至比内存的随机访问要快。

# 存储架构
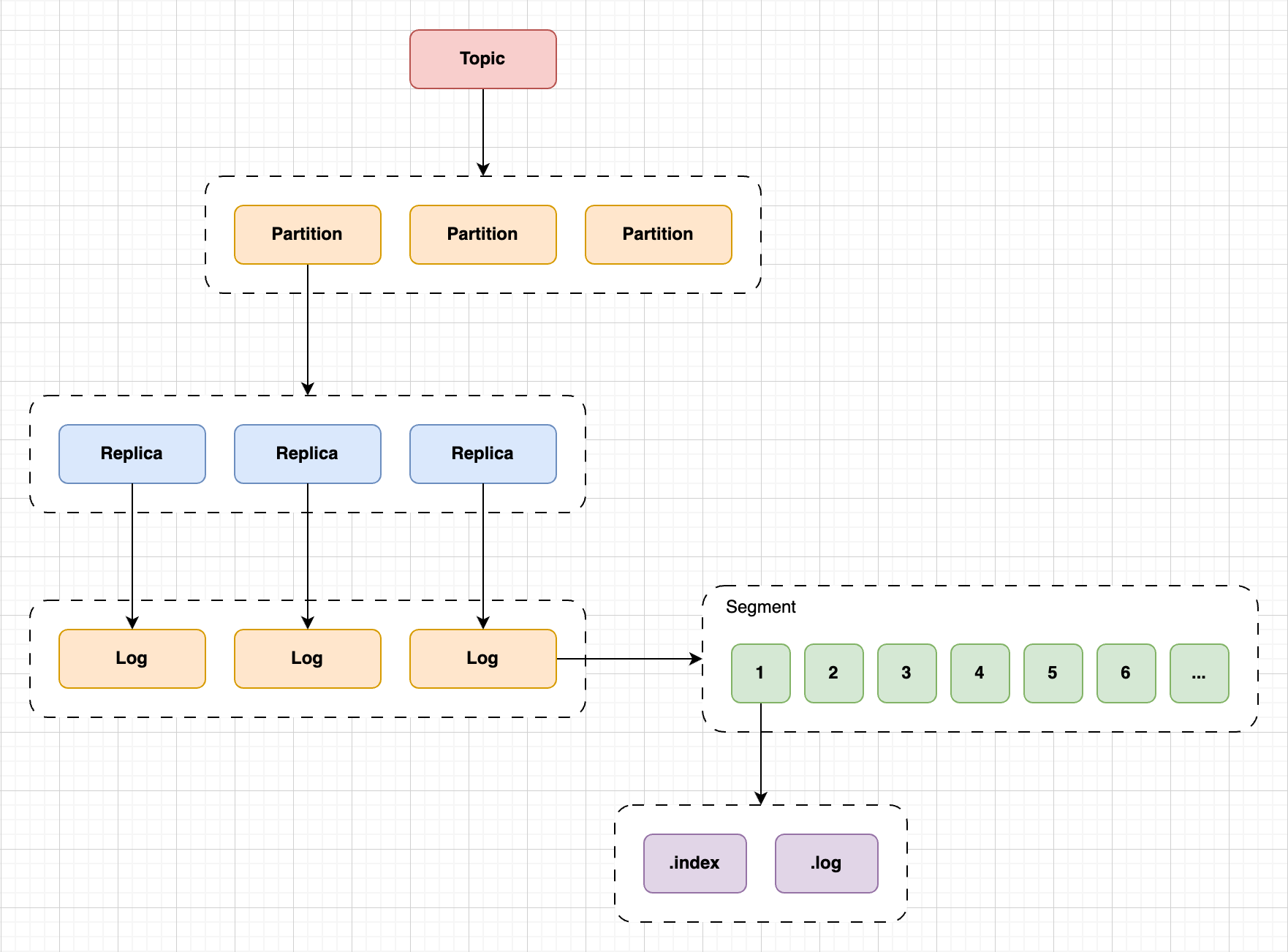
上图是 Kafka 存储架构,Kafka 是基于「主题 + 分区 + 副本 + 分段 + 索引」的结构:
- Kafka 中的消息是通过 Topic 进行归类的,这里的 Topic 是逻辑上的概念,实际存储消息的是 Partition。Topic 可以分为多个 Partition,可以在创建 Topic 时指定分区数。
- Partition 分区主要是为了解决 Kafka 存储的水平拓展问题,多个 Partition 可以分布在集群中的多个 Broker 中,避免数据过大而出现的性能瓶颈。此外,每一个 Partition 分区还可以指定副本数目,提高集群的可用性。
- Partition 分区的数据存储在日志文件在,为了防止单个文件过大,Kafka 将日志文件分为多个 Segment File,也就是将一个大文件分为多个小文件,这样便于消息的查找、维护和清理。
- 每一个 Segment File 分为两个文件,分别是
.log和.index文件,.log文件是实际存储消息的文件,.index文件用来索引消息,提高查找效率。每个partiton只需要支持顺序读写就行了,segment文件生命周期由服务端配置参数决定。。
# 存储方式
首先,我们先讲一下 Partition 的存储形式。
Topic 是一个逻辑层面的东西,当我们创建一个 Topic 时,实际上是创建了 Partition 分区,这些分区以目录的形式存储在存储路径下。Kafka 可以通过修改 server.properties 配置文件的 log.dirs 配置项来指定日志的存储路径,比如 log.dirs=/data/kafka-logs 。在这个目录下,Topic 会以【Topic 名称-分区编号】的形式存在,编号是从 开始。下面创建两个 Topic,分别是 alarm-info 和 order-info ,各自有 个分区。
tree -d 命令将当前目录下的文件夹列出来
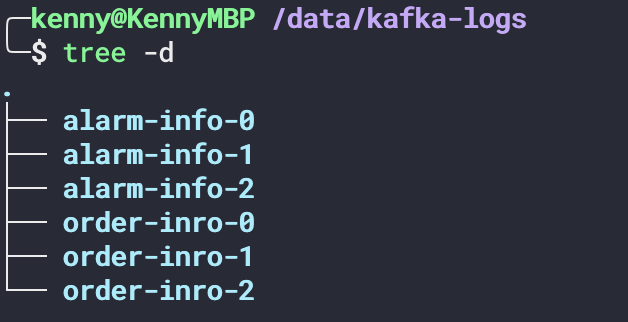
当我们展开分区目录时,可以看到这个目录下有 .log 和 .index 文件(下面称为 Segment File),.log 文件是实际存储消息的文件,.index 文件用来索引消息,提高查找效率。但数据越来越多的时候,这些数据会被存储在多个不同的 Segment File 中。
(图片来自网络)

- Segment File 组成:由2大部分组成,分别为
.log和.index文件,此 2 个文件一一对应,成对出现。 - Segment File 命名规则:Partion 全局的第一个 Segment 从0开始,后续每个 Segment 文件名为上一个 Segment 文件最后一条消息的 offset 值。
index 文件为 log 文件的消息提供了索引,具体是提供某条消息所在的位置。

索引文件存储大量元数据,数据文件存储大量消息,索引文件中元数据指向对应数据文件中 message 的物理偏移地址。 其中以索引文件中元数据 3,497 为例,依次在数据文件中表示第 3 个 message (在全局 partiton 表示第 368772 个 message)、以及该消息的物理偏移地址为497。
# 消息结构
.log 文件存储的实际的消息,一条消息在硬盘中的存储格式如下:
offset : 8 bytes
message length : 4 bytes (value: 4 + 1 + 1 + 8(if magic value > 0) + 4 + K + 4 + V)
crc : 4 bytes
magic value : 1 byte
attributes : 1 byte
timestamp : 8 bytes (Only exists when magic value is greater than zero)
key length : 4 bytes
key : K bytes
value length : 4 bytes
value : V bytes
2
3
4
5
6
7
8
9
10
其中,左边是字段,右边是字段可能占用的字节数。
| 字段 | 说明 |
|---|---|
| offset | 在 Partition 中的每一条消息都会有一个唯一的 ID,称为偏移,它可以唯一确定每条消息在 Partition 中的位置 |
| length | 消息的长度 |
| crc | CRC 校验码 |
| magic value | 表示本次发布Kafka服务程序协议版本号 |
| attributes | 表示为独立版本、或标识压缩类型、或编码类型 |
| timestamp | 消息的产生时间 |
| key length | 当消息有指定 key 时,表示 key 的长度 |
| key | 消息的 key,可以不填 |
| value length | 实际的消息的长度 |
| value | 实际的消息数据 |
# 消息的寻址
例如读取 offset=368776 的 message,需要通过下面 个步骤查找。
- 第一步查找segment file 上述图2为例,其中 00000000000000000000.index 表示最开始的文件,起始偏移量(offset)为0。第二个文件 00000000000000368769.index 的消息量起始偏移量为 368770 = 368769 + 1.同样,第三个文件 00000000000000737337.index 的起始偏移量为737338=737337 + 1,其他后续文件依次类推,以起始偏移量命名并排序这些文件,只要根据 offset 二分查找文件列表,就可以快速定位到具体文件。 当 offset=368776 时定位到00000000000000368769.index|log
- 第二步通过 Segment File 查找 message 通过第一步定位到 segment file,当 offset=368776时,依次定位到 00000000000000368769.index 的元数据物理位置和 00000000000000368769.log 的物理偏移地址,然后再通过00000000000000368769.log 顺序查找直到 offset=368776 为止。
从上述图3可知这样做的优点,index 文件采取稀疏索引存储方式,它减少索引文件大小,通过 mmap 可以直接内存操作,稀疏索引为数据文件的每个对应 message 设置一个元数据指针,它比稠密索引节省了更多的存储空间,但查找起来需要消耗更多的时间。
# 参考文章
- https://tech.meituan.com/2015/01/13/kafka-fs-design-theory.html
- https://ost.51cto.com/posts/11167
- https://waylau.com/apache-kafka-quickstart/
